The Future of Coding community has a Slack that I love to hang out in. I've argued against making the archives public, but occasionally I put enough effort into a post that I actually do want it to be discoverable. Here are some.
[Make me think!] is a lovely article, but […] it has a lot of bad takes:
It's certainly a failure of the way user-centered design is practiced that designers so often neglect a person's need to be empowered to learn, a person's need to be resilient in the case of failure, and a person's need to understand the consequences of their actions. But if you find yourself practicing user-centered design for FoC, you're going to be thinking about those needs just by the nature of your project, and there's no reason you couldn't take those same biases with you to any other project, or convince other designers that they're important.
Also, black boxes are not the problem to be solved, and complicated → simple → too simple is not just a matter of complexity changing hands. If you made some translation software and were concerned about a person's need to wean themself off of it and have fun by actually learning the language, it doesn't matter that the translation happens in a black box. No fraction of exposed translation technology is going to empower them to learn the language. To do a good job, you're going to invent wholly new complexity in the form of a language learning system for which some of the complexity is in the user's hands and some is in the designer's. Nothing about black boxes prevents you from satisfying that need. Similarly, car engines are too complicated for everyone to understand, but designers address your need for resilience to engine failure not by exposing parts of the engine, but by adding a totally separate backup system that's easily understood: the hooks that allow you to attach your car to another.
So I wouldn't jump immediately to making white box systems. If you're consciously reacting to a person's needs, chances are that you'll think of more ways to do that than exposing the system's guts.
I work with XXX’s so-called boring accounting state machines day-to-day (they are boring :). But even the simplest is governed by events that are coming from devices all over the world, aggregated in servers all over the world, fed into streaming or batch event processors… To answer “What state is a user in?” with the value that’s stored in a particular database misses so much. Sometimes the value isn’t anywhere, because it’s defined as the output of a computation based on other states. People generally choose whichever version of the answer is nearest at hand. “Let’s read it from here instead of there because this data source is updated more frequently.” Every read of a state is an estimation process.
So I have a hard time imagining what “collecting state transition logic” could possibly look like. I feel like the scope has to be exceedingly small for that idea to make sense. Even at the app level, you have event loops and synchronization and subsystem boundaries introducing propagation delays that make it difficult to say what a state is. (Race conditions!)
But maybe you just need an exceedingly homogenous programming environment along the lines of Unison to make those big systems seem small? Or Eve-like global synchronization?
Did you ever look into Fiat? I saw it come up in the comments and after skimming the paper, my interest is piqued!
The foundation of deductive synthesis in Fiat is refinement: a user starts out with a high-level specification that can be implemented in any number of different ways and iteratively refines the possible implementations until producing an executable (and hopefully efficient) implementation.
http://plv.csail.mit.edu/fiat/papers/fiat-popl2015.pdf
However, I have no experience with this notation, so I can’t understand almost any of the figures…
I wonder what the experience of using Fiat is like.
Does it degenerate to requiring so much specification that there's no interesting variance in the programs that it writes? Maybe that’s a better way to arrive at that program because what you write decomposes by feature rather than by computational step, but I’m still curious what that process is like for a programmer on average.
Another question is, if your code is used non-deterministically to write programs, how do you convince yourself that you’re done—that you won’t get some degenerate “return null” implementation next time you compile because you overlooked a hole in your spec? Do you add unit tests? The initial Cache ADT in the paper had that problem; it described a cache algorithm family that contained every cache algorithm including the one that never adds anything to the cache. The authors knew it had that problem, but in general, how do you?
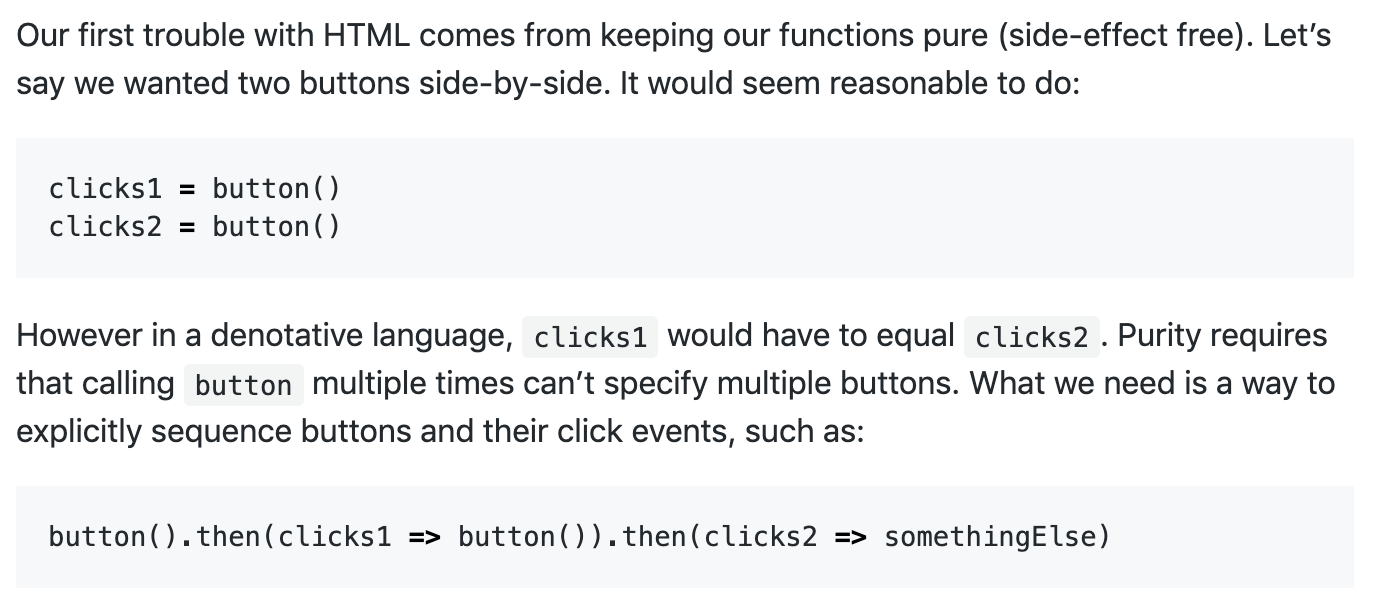
@XXX (or anyone more well read on this than me), I enjoyed https://futureofcoding.org/essays/dctp.html but I got tripped up on the part I snipped below. Is there any reason why you chose to sequence the buttons instead of expanding the domain of button?
Like, if the buttons were presented on something like a graphic then it might be clicks1 = button(rect1); clicks2 = button(rect2). Or if there were a layout engine, maybe something like clicks1, clicks2 = stacked((a, b) → (button(a), button(b))). Would that also resolve the issue?
For context, see this Twitter thread.
How about some literate programming, elastic tabstops, hyperlinks, and schematic tables?

@XXX I don't think so, but it's just because you're talking about the quality of the communication and I'm talking about the amount. I'm saying that when protocol boundaries match team boundaries, cross-team discussion is only ever needed when the protocol changes, whereas without protocol boundaries, the teams potentially step on each other's toes with every change.
You're right about maintainability, but today it's very easy technologically and organizationally to enforce a single programming language across the organization, whereas it's nearly impossible for people to collaborate in multiple languages at any level smaller than a server. That's a lever that we just can't pull, even in cases where it might make collaboration more efficient.
A type of collaboration I see a lot is when my team needs another team's expertise. An RPC protocol can be written to satisfy almost any language's type system guarantees, so theoretically the only difference between calling a method written in the same language and one in a different language should be where the computer looks for the implementation. But when I ask a team of machine learning experts to write a GetRecommendedMovies() function for my web site, and their preferred ML library is TensorFlow, their implementation strategy varies dramatically based on which language I want to call the function from [ed: if Python, it's straight-forward; if C, think about FFI restrictions; if Ruby, maybe sockets are involved]. I don't think we necessarily want that collaboration overhead. Usually, we don't gain anything from it.
And if in the course of writing GetRecommendedMovies(), they accidentally introduce a memory leak, does the user get a connection-lost error because the whole server goes down, or is the movie recommendation part of the page just empty because I handle the error on my side? Do I have to fix their bug to work on other parts of my page?
And if I want to continue development with a working version of their code (not just a black hole that behaves as if the function never existed), do I have to root cause the bug to figure out which commits to revert, or can I just back out all of that team's changes (the ones on their side of the protocol boundary) from the past week? Can I do that without losing everyone else's changes from that same period?
This is the shape of my collaborative coding dream.
A few months later…
Just had a great experience collaborating at work yesterday. I’m in Japan this week for a prototype sprint, paired with another engineer. His ML component took a few days to build, so we defined a protocol (over gRPC—actually pretty easy because his team had already been using protocols for collaboration, so we just recombined a few [specs]), then split up. I wrote a stub implementation in Go that I could use until his C++ service was ready. I kept telling him it’d work the first time, but he wouldn’t believe me… until he finished, I switched the address to point to his laptop instead of my in-memory stub, and it worked seamlessly!
I keep the stub around for when his laptop is down or his code is broken because he’s iterating simultaneously with me.
We’ll probably move it all into the same computer for the demo, but maybe not.
This is easy collaboration!
Hickey had that whole talk about decoupling the various semantics of "map" just to the extent that it could run in serial or in parallel, and it's just plain impossible for every engineer to put that amount of thought into every bit of code they write. I feel that most of the lack of reuse / repo bloat is just that: someone writes a module that complects the type of input, type of output, programming language, runtime, threading model, framework, etc, and separating any of those is just so hard that it gets rewritten instead, but with all the same rigidness in a new configuration because it's still hard to write in a factored way.